Hello Matthieu,
As Yvan said, a direct solver has a memory consumption which is much higher than an iterative solver. The reading of your log files is clear : Elapsed time for the full computation = 29791s and elapsed time in solving the NavSto system = 29679s
Moreover, there are some differences in the CDO part w.r.t. the FV part of code_saturne. The Navier-Stokes system to solve is a coupled system (velocity, pressure). The resolution is an Augmented Lagrangian Uzawa (please refer to https://hal.science/hal-04087358/document for more details) which increases the stencil of the discretization with the add of a grad-div contribution.
Since the velocity unknowns are located at faces (all the components), the velocity block which is solved by MUMPS is of size 33n_cells for a 3D Cartesian mesh. In a 3D mesh built from a one-layer extrusion, this is worse 34n_cells. So the system to solve with MUMPS is of size 3M.
To speed-up the calculation (but do not wait for miracles), here are some ideas :
(a) use 1MPI and 8openMP (or 2MPI and 4 openMP) since the scaling of MUMPS is not as good as the scaling of code_saturne
(b) compile MUMPS with optimized BLAS (there many operation relying on BLAS3 and this can bring some improvements)
(c) Optimize the MUMPS options : choice of the renumbering algorithm (this can slow down the analysis step but speed up the factorization step which is the most time consuming) for your kind of grids AMD or QAMD could be better than the default choice, use analysis by block (this is a vector-valued system).
You can specify all available options of MUMPS using the following function
#if defined(HAVE_MUMPS)
/*----------------------------------------------------------------------------*/
/*!
* \brief Function pointer for advanced user settings of a MUMPS solver.
* This function is called two times during the setup stage.
* 1. Before the analysis step
* 2. Before the factorization step
*
* One can recover the MUMPS step through the "job" member.
* MUMPS_JOB_ANALYSIS or MUMPS_JOB_FACTORIZATION
*
* Note: if the context pointer is non-NULL, it must point to valid data
* when the selection function is called so that structure should
* not be temporary (i.e. local);
*
* \param[in] slesp pointer to the related cs_param_sles_t structure
* \param[in, out] context pointer to optional (untyped) value or structure
* \param[in, out] pmumps pointer to DMUMPS_STRUC_C or SMUMPS_STRUC_C struct.
*/
/*----------------------------------------------------------------------------*/
void
cs_user_sles_mumps_hook(const cs_param_sles_t *slesp,
void *context,
void *pmumps)
{
CS_UNUSED(slesp);
CS_UNUSED(context);
DMUMPS_STRUC_C *mumps = pmumps;
assert(mumps != NULL);
/* Choose the way numbering is performed inside MUMPS.
* This option may have a strong effect on the elapsed time
* 0: AMD
* 3: Scotch (need a MUMPS library compiled with Scotch)
* 4: PORD
* 5: METIS (need a MUMPS library compiled with METIS)
* 7: automatic choice done by MUMPS
*/
if (mumps != NULL)
mumps->ICNTL(7) = 0;
/* Adapt any option from the MUMPS user book following the previous example */
}
#endif /* HAVE_MUMPS */
One more thing (only possible for 3D mesh with one layer extrusion). It is possible to “remove” from the linear system extruded boundary faces. Here is an example with boundary faces tagged with “Z0” or “Z1” (adapt this example and add it to a cs_user_mesh.c file)
/*----------------------------------------------------------------------------*/
/*!
* \brief Apply partial modifications to the mesh after the preprocessing
* and initial postprocessing mesh building stage.
*
* \param[in,out] mesh pointer to a cs_mesh_t structure
* \param[in,out] mesh_quantities pointer to a cs_mesh_quantities_t structure
*/
/*----------------------------------------------------------------------------*/
void
cs_user_mesh_modify_partial(cs_mesh_t *mesh,
cs_mesh_quantities_t *mesh_quantities)
{
cs_lnum_t n_faces = 0;
cs_lnum_t *face_ids = NULL;
BFT_MALLOC(face_ids, mesh->n_b_faces, cs_lnum_t);
cs_selector_get_b_face_list("Z0 or Z1", &n_faces, face_ids);
cs_preprocess_mesh_selected_b_faces_ignore(mesh,
mesh_quantities,
n_faces,
face_ids);
BFT_FREE(face_ids);
}
When I apply all these options/techniques, I may achieve a speed-up up to a factor 5 or 6.
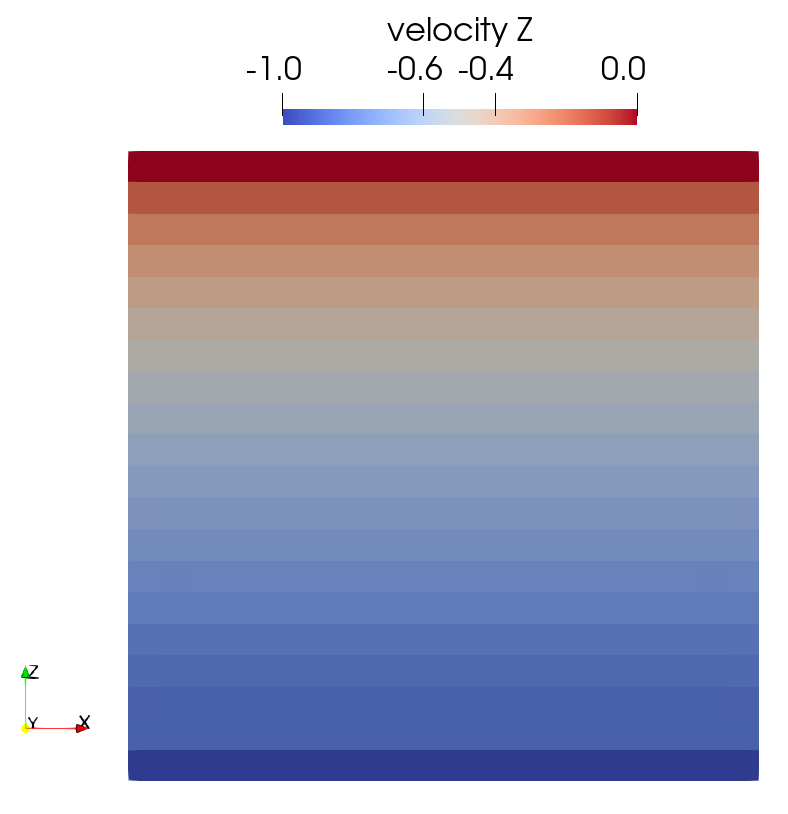
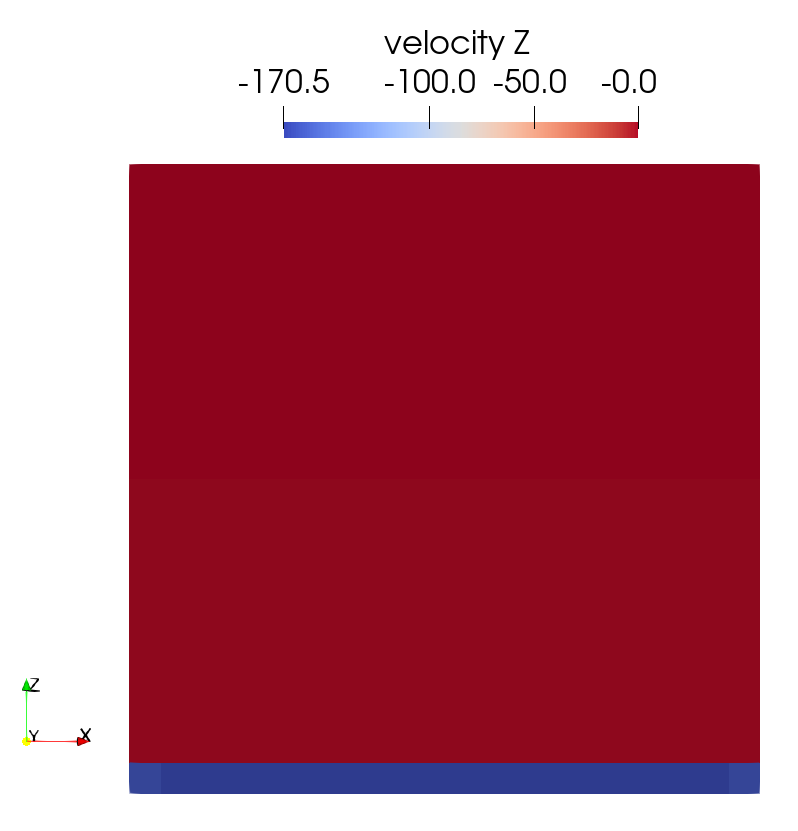
For the second question, it seems that the non-linear algorithm (Picard algo.) does not converge. The max. number of iterations is reached.
Could you please send me your settings ?
I think that a first test is to switch to a linearized algorithm and see what happens. It may be useful to reduce the time step for the first iterations. I can adapt your settings to do this.
Best regards,
Jerome